
MySQL PerformanceAn important work-load for many users is that of a database server. Such a server needs to respond to requests for information from its clients. In doing so, memory needs to be allocated to process these requests, and return the results. Since the speed of a database server is extremely important for many businesses, many people spend a huge amount of effort tuning their servers to gain as much performance as possible. It turns out that memory allocation can be the key bottleneck in such systems. This has led to the addition of the A customer of Lockless Inc. sent us the following benchmark results for a system with an 8 core Xeon X5355@2.66ghz, 8GiB RAM, 4x15kRPM HDDs in RAID10. The system was running linux, in 64bit mode. Using the command 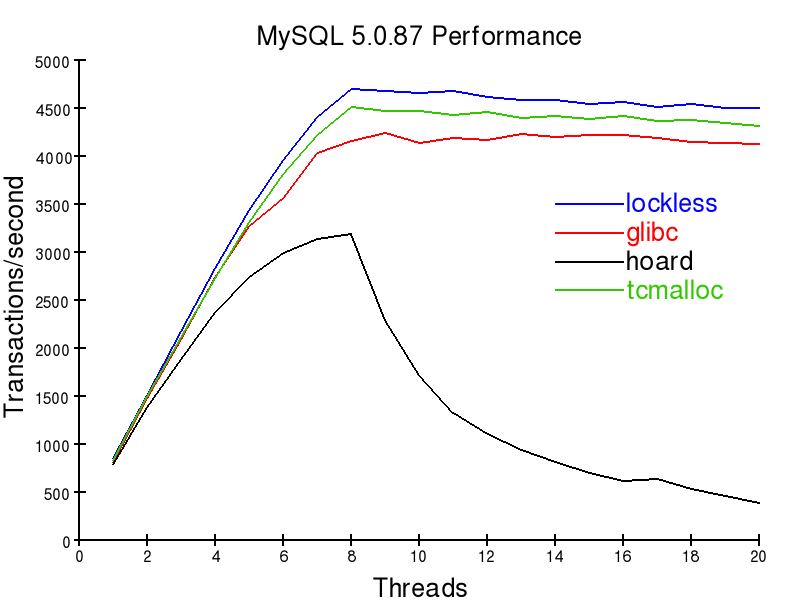
As can be seen, the number of transactions per second can be strongly affected by the memory allocator you choose to use. Some allocators scale to using all eight of the machines cores, others do not. This isn't the whole story, though. A real database server is usually under a read-write load. However, benchmarking such a load isn't quite as clean-cut. The problem here is that there are two different possible ways to measure performance. The above graph shows throughput. The higher the throughput, the better. There is one other important factor though, latency. If your users end up waiting too long for your database server to respond, your website or point of sale system will appear sluggish and slow. Unfortunately, the real performance of a server is combination of throughput and latency, and not a single number. The difference between the two factors is increased by poor parallel design of the underlying memory allocator. If a server thread is continually waiting on a lock, then it both gets no work done, and increases latency. Conversely, if a thread "hogs" a lock, then it may get an unfair share of work done. This results in "jittering" in performance, with your request time dependent on the luck of the draw about whether or not your thread already having the key memory lock. The customer with the above test system also had a production system with extra performance patches, and rebuilt with profile-guided-optimization using the Intel C Compiler. The system handles about 2000 queries per second. According to the customer, the glibc allocator totally bottlenecks the system. It uses 300% cpu load maximally, and queries can take greater than five seconds to respond. This is due to a horrible amount of locking contention between the database server threads. Hoard was better than the glibc allocator for this load, and tcmalloc better again. The tcmalloc case was a little "jittery" under load, and could use up to 700% cpu, corresponding to seven cores of the eight core machine. The average cpu use was 450%. Unfortunately, the machine needed to be restarted weekly due to the fact that the tcmalloc allocator doesn't free memory. According to the customer, the Lockless allocator ran smoothly under the same load, averaging 150% CPU use. It could use all eight of the cpu cores, providing a larger amount of head-room for peak load situations. It also didn't require any reboots, due to the allocator freeing memory it doesn't need. Depending on your (MySQL) database load, you may also obtain similar results with the Lockless memory allocator. It may be possible to save a large amount on hardware costs, or to improve the utilization of hardware you already own. If anyone else has had interesting experiences in optimizing database servers by altering the default memory allocator, feel free to comment below. |
||
| About Us | Returns Policy | Privacy Policy | Send us Feedback |
|
Company Info |
Product Index |
Category Index |
Help |
Terms of Use
Copyright © Lockless Inc All Rights Reserved. |


Comments
Joe said...(btw: your CAPTCHA is too long, it's taken me 8 tries..)