
MPI BenchmarksThe fact that Lockless MPI uses threads instead of processes means that address space is shared between MPI ranks on the same machine. This in turn means that less copies are required, improving performance. Finally, wait-free queues are used to martial the data, reducing locking overhead to a single bus-locked instruction per send or receive. We compare performance against MPICH2 version 1.4.1, and OpenMPI version 1.4.3, testing on a dual dual-core opteron 280: 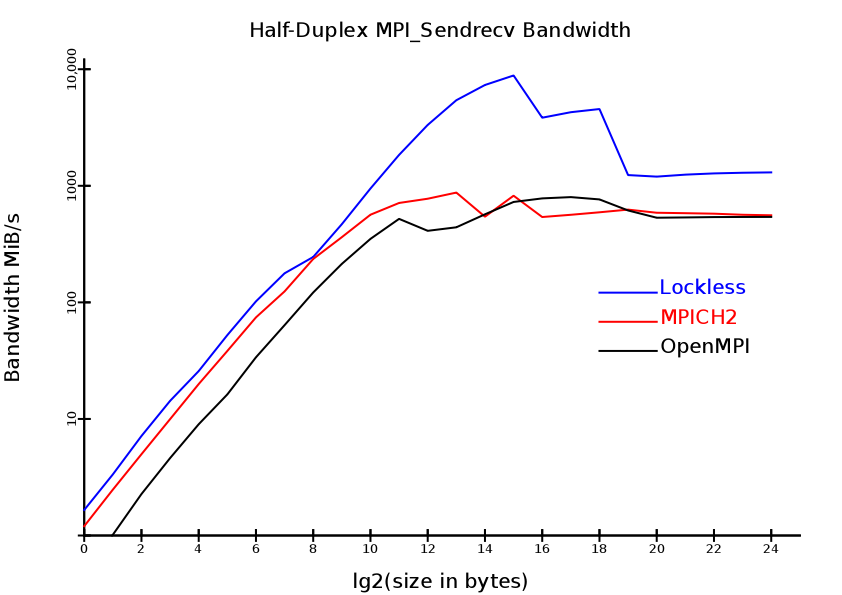
The above graph uses the time taken to The smallest messages are latency bound. This shows as the straight-line behaviour below about 1KiB. The messages complete in a time that is relatively constant, so doubling the size of the messages will roughly double the effective bandwidth in this regime. As can be seen, Lockless MPI obtains the highest bandwidths due to having the lowest latencies. It is about 40% faster than MPICH2, and nearly three times faster than OpenMPI in this region. The difference in speed seems to be due to the extra locking that the other MPI implementations do. The addition of a single extra bus-locked instruction reduces the Lockless MPI advantage back down to something that would be nearly the same speed as MPICH2. The behviour at the largest message sizes also has a relatively simple explanation. Here, the MPI implementations are memory-bound. Their speed depends on the number of copies that they do. Since Lockless MPI does half as many, it is at least twice as fast. However, the speed advantage is even greater than that. Since other MPI implementations need to copy via a buffer in shared memory, the non-optimal use of that buffer can be a cause for speed loss. If the buffer is over, or underrun buy the send or receive sides respectively, that side will need to wait. The end result is that Lockless MPI is about 2.4 times as fast in this region. The middle of the graph is more complex, describing the switch over between latency and memory being the limiting factor. As can be seen, the other MPI implementions roll over nicely at around their limit large-size bandwith, without much complexity. Lockless MPI is different, and has two "steps" in the graph. These correspond to the bandwidths of the L1 and L2 caches. By using L1 more efficiently, Lockless MPI can obtain more than an order of magnitude speed improvement compared to other MPI implementations. The efficient use of L2 also provides a more modest advantage. |
||
| About Us | Returns Policy | Privacy Policy | Send us Feedback |
|
Company Info |
Product Index |
Category Index |
Help |
Terms of Use
Copyright © Lockless Inc All Rights Reserved. |

